https://github.com/MarcoAurello/Estudo-DataSets/blob/master/codigo
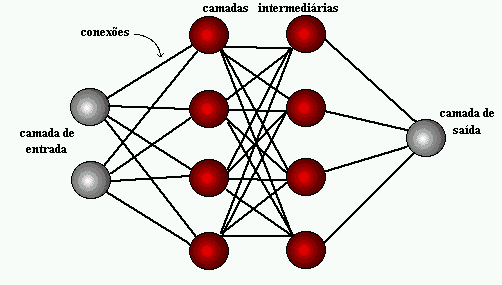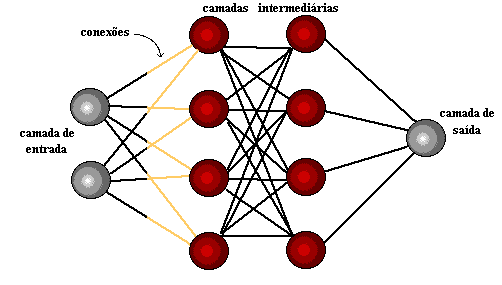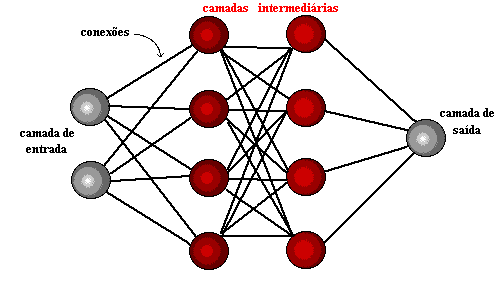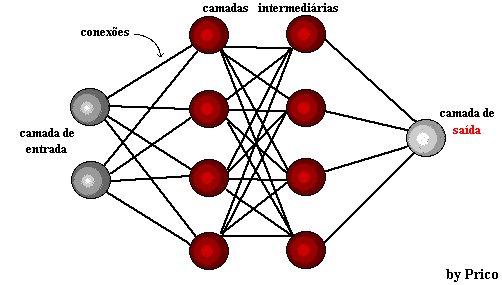
Rede Neural e uma das ferramentas da Machine Learning que busca imitar o aprendizado humano usando a arquitetura de funcionamento do neurônio, onde dependendo do tamanho do problema podemos usar mais ou menos neurônios para resolução.

{kind=link}
Aprendizado por Referência:
O celebro humano precisa de referências para aprender, ao olhar para um objeto novo pela primeira vez, nosso celebro busca referências em outros objetos já fotografados pelo nosso olhar, quando não temos referências de algo parecido em nosso cerebro precisamos ver o objeto ser usado para conseguir classifica-lo.

Mapeamos a necessidade de uma ferramenta de inteligência para ajudar a descobrir se o funcionário terá o desempenho desejado a médio prazo.
Vamos criar um modelo de apoio a decisão usando redes neurais. Escolhi 5 variáveis para criação do modelo:
-Organização da mesa de trabalho
-Pontualidade
-Trabalho em equipe
-Comunicação
-Produtividade
Estas variáveis não foram escolhidas por acaso, foram apontadas com uma variância alta entre funcionários motivados e desmotivados.
A rede neural que iremos criar precisa de uma base de dados para treinamento, sabemos que o neurônio precisa "aprender" para poder classificar. Antes de analisar se o funcionários vai ter um bom ou mau desempenho, temos que mapear e pontuar funcionários já existentes. Esta base de dados vai ensinar nossos neurônios artificiais a prever o desempenho do funcionário.
Importante:
Algumas métricas foram usadas para que a apuração das notas seja eficaz, esta etapa e importante pois as notas devem ser parecidas independente de quem esta avaliando o funcionário, para isso precisamos de uma métrica que informa os parâmetros das notas e da produtividade.
No arquivo a baixo pontuamos e qualificamos alguns funcionários para treinar nossos neurônios.
notas de 0 a 5 de acordo com métrica criada.

Apos captar todos os dados passamos para o Excel e salvamos em modo csv. temos 4 variáveis quantitativas, e uma variável qualitativa com 4 valores possíveis.
Desempenho: Ruim, Regular,Bom, Otimo

No software R importamos a biblioteca neuralnet que fará a modelagem da nossa rede de neurônios.

Carregamos a planilha na variável dados, em seguida fazemos sua exibição em fix() para conferir se esta tudo certo.

Preciso gerar 4 novas colunas, uma para cada status do desempenho, onde classificamos como verdadeiro a coluna correspondente ao status correto, veja com atenção os comandos e a planilha gerada abaixo, temos o valor verdadeiro somente na coluna referente ao status do desempenho.

Uso o método cbind() para criar as 4 novas colunas, veja na linha de cada funcionário que só consta como verdadeiro TRUE a coluna referente ao desempenho do mesmo as outras estão setadas como FALSE.
Vamos agora alterar o titulo das colunas para facilitar nosso processo.

Iremos usar 70% dos dados para treinar o modelo e 30% para testar sua efetividade, usaremos então um vetor de apoio, vamos ajudar a separar as duas amostras.

Vamos agora usar o vetor amostra para separar nosso arquivo de dados em 2 arquivos.

Variável dadosTreino tem 15 funcionários como vemos com o metodo dim(), este arquivo vai treinar o modelo.
Variável dadosTeste tem 5 funcionários, iremos usar este arquivo para testar se o modelo está prevendo corretamente o desempenho dos funcionários.
Vamos a criação do modelo:
com a função neuralnet() passamos as colunas criadas acima, a base de dados de treino, e a quantidade de camadas de neurônios usados. Para ver a documentação do pacote neuralnet() clique aqui
Modelo criado:

Testando o modelo criado:
Vamos agora aplicar o modelo criado ao arquivo dadosTeste com o método compute(), o fragmento [,1:4] estou passando somente as 4 colunas com as novas notas.

Vamos agora tratar o arquivo para a comparação, usamos a função as.data.frame() para criar a variável resultado, e nomeamos as colunas deste novo dataset.

Vamos dar uma olhada no resultado.

Temos os valores probabilístico dos 5 funcionários, devemos escolher a coluna com o maior numero. funcionário 3 =Ruim 5=regular.
Para criar uma matriz comparativa devo criar uma nova coluna com o maior valor de cada funcionário. Criamos abaixo a coluna desempenho no data set resultado, selecionando o maior valor das 4 colunas.

Temos abaixo a tabela para confrontar os desempenhos gerados pelo modelo resultado$desempenho, e o real desempenho mapeado por quem aferiu o desempenho do funcionário, neste caso obtivemos 100% de acerto, o modelo parece esta bem ajustado, repare o numero zero em destaque caso por exemplo foce 1 indicaria que um funcionário ótimo foi clarificado como bom pelo nosso modelo

Vamos agora gerar o desempenho de novos funcionários, importamos o arquivo csv com as notas e sem a coluna desempenho.
apos a aplicação e o tratamento do arquivo temos os desempenhos gerados pela nossa rede neural.

“Essentially, all models are wrong, but some are useful”